

Image recognition, especially, facial recognition is nothing new to casual users of smartphones and social networks. Many social networks including Facebook has been using facial recognition to suggest the names of “friends” while tagging newly uploaded photos. With increasing confidence values provided by modified algorithms, apps like Facebook Moments now boldly suggests that you send photos to recognised friends who feature in them. Extensive research work is being carried out in the domain of image recognition by academics and companies to further this kind of applications. In a paper titled “DeepFace: Closing the Gap to Human-Level Performance in Face Verification”, Taigman et. al. have proposed an approach for face recognition in unconstrained images which performs remarkably with an “accuracy of 97.35% on the Labeled Faces in the Wild (LFW) dataset”. That is almost at the brink of human level accuracy!
In this article, I am going to informally evaluate a new application Facebook is putting its algorithms into. A few months ago, Facebook announced that to aid the perception of photos by differently abled users who have impaired eyesight, it is going to add detected features in the alt-text of images which can then be used by text-to-speech applications to describe the image contents.
Background about HTML Alt-Text
Alternate texts are provided in an HTML page along with certain types of content such as images, which are intended to provide a textual description for them if the page is loaded in a browser which does not support the content. This is also useful in slow networks when the alt-text is typically visible till the image has loaded to a certain extent, or when the image cannot be accessed for some reason. If one previews the HTML content of such an image by accessing the source HTML, he/she will be able to find an image tag “<img …>” with an “alt” attribute containing the alt-text content.

Evaluation Methodology
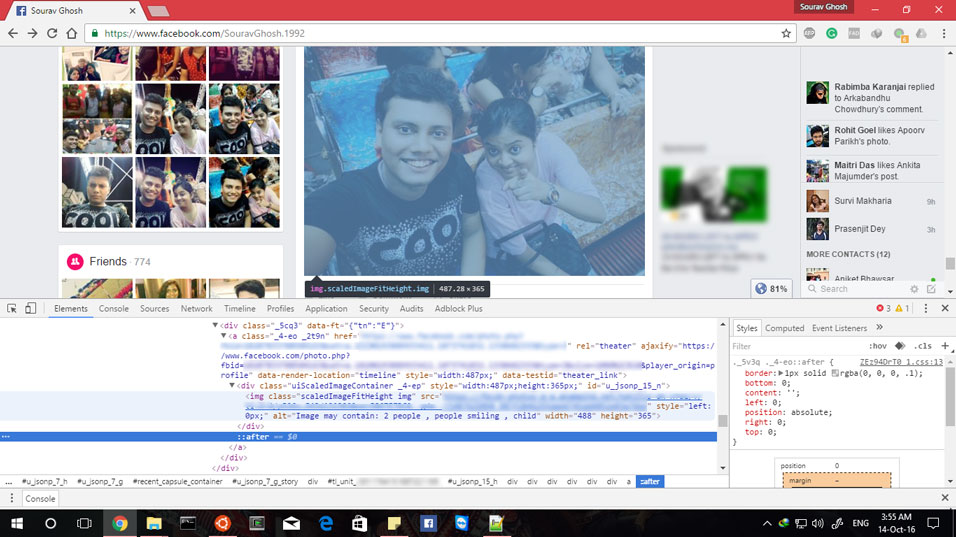
In order to evaluate the accuracy of Facebook’s innovative usage of image recognition for improving accessibility, I have tested its output on some images uploaded by me on the social network. To view a relatively smaller number of images manually, one may inspect the page contents by right-clicking on the image and selecting the “Inspect element” option in the context menu. Then, the task is only to locate the “img” tag (modern browsers make it very easy to locate) and then the adjoining “alt” attribute. The content of this “alt” attribute is the concerned output of Facebook’s algorithm.
Among the image contents, the primary observable objects present (which are at least ~80% visible) are of higher priority in the list of features detected. The count of such objects observed contributes to TRUE POSITIVES. The count of objects which are prominently visible but not listed in the output list make up the FALSE NEGATIVES. Similarly, the count of listed items which are not present but listed is considered as FALSE POSITIVES. To get an estimate of TRUE NEGATIVES, the count of items which are detected in other test images but not in the current image is used as a measure.
Output of the Feature Detection algorithm
While the evaluation process has been automated (obviously with manual tagging), the output in certain cases is listed here using a manual approach, to explain the idea of the above calculation. The output contains some accurate classification as well as errors ranging from quite permissible mistakes like identifying faces of idols as human faces to relatively bizarre ones although their frequency is rare. Following are few examples:





Summarised Result
A summarised result of the observations normalised to 1 is as follows:
| Prominently visible | Not visible | |
| Detected | 0.792
(TP) |
0.387
(FP) |
| Omitted | 0.208
(FN) |
0.613 (TN) |
Disclaimer: As the dataset used is not very large and might be biased by my selection of images, evaluation results may not be treated as reflective of the true performance of the algorithm.